How AIs Learn
TL;DR: AIs don't think. They learn patterns from data through tokenization, parameters, and training methods like RLHF. Understanding this helps you work with them more effectively.
What to expect:
- What tokens, context windows, and parameters actually are
- The difference between LMs, LLMs, and Foundation Models
- What temperature is and why it matters
- How supervised, unsupervised, and self-supervised learning work
- What RLHF does and why it matters
- Why data quality beats quantity
Yes, the images have Gemini watermarks. No, I don't pay for Gemini Pro. Claude Max is already taking all my AI budget.
Introduction
As someone who uses AIs every day, and as a software engineer, I have both the curiosity and the need to understand how things work under the hood.
When we interact with AI models like ChatGPT or Claude, it feels almost magical: you type a question, and you get a coherent, intelligent response.
But what's actually happening under the hood? How do these models "learn" to understand and generate human language?
This post breaks down the fundamentals of how modern AI models learn, drawing from concepts covered in the AI Engineering book, by Chip Huyen.
Whether you're an engineer looking to work with AI or just curious about the technology, understanding these concepts will give you a clearer picture of what AI can and can't do.
AI Models
First things first, let's make something clear from the start:
AIs don't think, nor do they have emotions. They just probabilistically return an output based on an input.
That is the reason why the same input can return many different outputs.
An AI model (also known as language model) is a software program trained on a massive set of data to recognize patterns and make decisions based on input data. It encodes statistical information about one or more languages.
Examples of AI models are: GPT, Gemini, Claude, etc.
Language Models, Large Language Models and Foundation Models
It's confusing to see those terms because they look the same, but they have differences.
Let's break it down:
Language Models and Large Language Models only differ in size. While LMs (Language Models) have millions of parameters, LLMs (Large Language Models) have billions to trillions of parameters.
So, the difference between them is only scale.
However, LLM is not an exact term, because the amount of parameters that is considered large today can be considered tiny tomorrow.
Foundation Models are a little different. While LMs and LLMs are trained only for texts, Foundation Models are trained for everything else: video, image, audio, etc.
If you're confused about what is a parameter, don't worry, there's a section for that.
Tokens: The Atoms of AI Language
The basic unit of a language model is a token. A token can be a character, a word, or part of a word, and that depends on the model. For example, a token for Claude can be different from the same token for Gemini.
Here is an example:
The phrase "Giovane is an awesome software engineer!" would be tokenized differently for Gemini 3 and GPT-5.
They look similar, but you can notice that my name was split differently between the 2 models. The process of splitting the phrases into tokens is called tokenization.
But why do models tokenize words?
There are three main reasons:
- Meaningfulness: Compared to characters, tokens allow models to break words into meaningful components. For example, "cooking" will be split into "cook" and "ing", with both components carrying meaning.
- Uniqueness: There are fewer unique tokens than unique words.
- Understanding: With invented words like "Midjourneying", splitting it into "Midjourney" and "ing" helps the model understand the structure and meaning, even if it's not an official word.
Parameters: The Model's Knowledge
You can think of parameters as the "knowledge quantity" of an AI model. Claude Opus model, for example, has trillions of parameters.
So you might be thinking: so, the more parameters, the better the model, right?
Well, not always. Here's why: a 1 billion parameter model trained with good data (science books, trustworthy websites, etc.) is more intelligent than a 1 trillion parameter model trained with junky data.
Of course, when we talk about big models like Gemini, Claude, GPT, we are talking about large models trained with good data, but in general, that's not a rule.
How AIs Learn
Right now, the most famous learning methods AIs use are:
- Supervised Learning, the guided student;
- Unsupervised Learning, the pattern finder;
- Self-Supervised Learning, the foundation;
- RLHF, the tuning.
Let's break down each of the methods.
Supervised Learning: Learning from Examples
In supervised learning, as the name suggests, the model learns from a dataset where the answers are already provided. For example:
- You give the model an image of a dog and say "That's a dog".
- You give a math problem with the result.
That is a good method for validating things with a limited amount of outputs, for example: classifying an email as spam or not.
Unsupervised Learning: Finding Patterns
In unsupervised learning, raw data is given to the model, and it learns from patterns and finds its own "correct" answers based on probability of token matching.
For example, given a shopping dataset, the model will notice that people who buy burgers also tend to buy ice cream.
That is good for: anomaly detection, customer segmentation, trends.
Self-supervised Learning: Foundation
In self-supervised learning, there's no human intervention at all.
The model reads a sentence, like "The book is on the []", it guesses "table", checks if it was correct, and adjusts its parameters. This process is called next-token prediction, and it's the core mechanism behind how modern LLMs generate text.
Since they don't require any labeled data, it's possible to construct a massive amount of training data by reading data from blog posts, wikis, comments, allowing models to scale up to become LLMs.
The issue with that is: there is no filter. You can grab misogynist, racist, sexist data from the internet since you're using everything. Again, AIs don't have feelings, so they don't know morals, ethics, or what's wrong or right.
To fix that and "humanize" AIs, we use RLHF, which we will discuss next.
RLHF: Aligning AI with Human Preferences
RLHF stands for Reinforcement Learning from Human Feedback.
The name is pretty suggestive. Humans "finetune" the models providing human feedback that aligns better with human preferences. "Humanizing" and "teaching" the models for certain types of answer.
For example, we ask the AI a question, and we have 6 answers, humans rank them, and the AI learns from that. It's simple, but must be rigorous, since that's one of the final steps before turning a model safe for public use.

Next-Token Prediction
The next-token prediction is the core engine of an LLM. It is the statistical process of guessing which piece of text (token) is most likely to come next based on the context.

We can separate the process in three steps:
- Context Window: the model looks at the prompt (e.g. "The capital of France is..."), as a sequence of numerical IDs.
- Probability Distribution: the model consults its parameters to calculate the probability of every token in its knowledge base. For "France is...", the probability of the next word being "Paris" is 90%, "Lyon" is 2%, and "Banana" is 0.001%. That's why the model picks Paris.
- Sampling: the model selects the next token (based on probability), appends it to the sequence, and repeats the process until the output is finished.
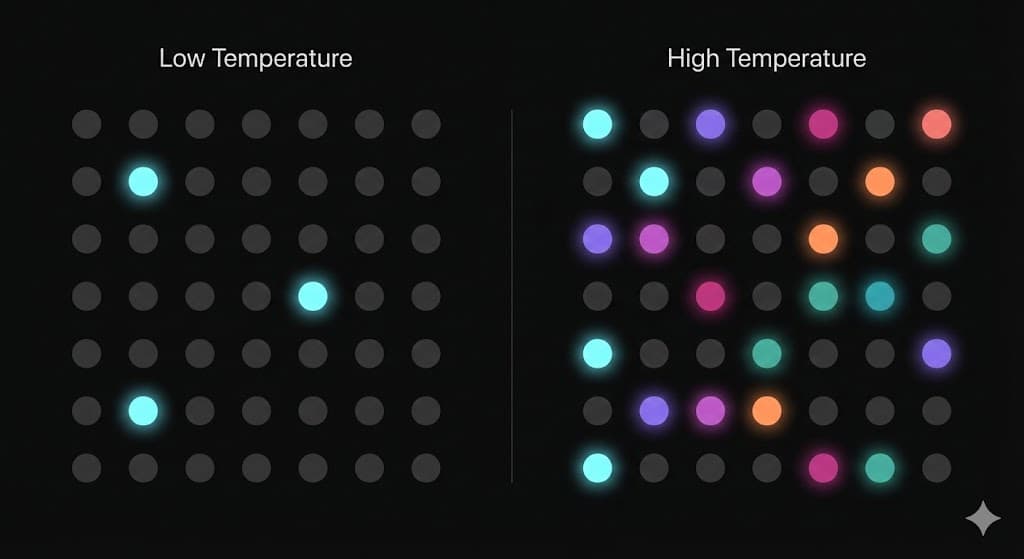
Temperature: Controlling Randomness
When performing the next-token prediction, the model calculates the probability of the next word. It usually has one clear winner and several losers (i.e. the capital of France example).
The temperature changes how a model chooses between them.
Low temperatures (e.g., 0.1 ~ 0.2) usually make the model "boring". Because it will always pick the token with the most probability, so, the model is most likely going to return the same thing for the same prompts. High temperatures (e.g., 0.8 ~ 1+) usually make the model more "creative". On high temperatures, the "winner" is still favored, but the "losers" have a much higher chance of being picked, making the output unpredictable.
Context Window
We can think of the context window as the model short-term memory. It is the maximum amount of text (measured in tokens) that the model can memorize at once to make its next prediction.
Let's take ChatGPT as example.
When we chat with it, it doesn't "remember" our past conversations. The entire conversation is sent back to it.
As long as the conversation fits within the model Context Window, it can "remember" everything discussed.
Usually, the larger the window, the better the model outputs.

Data Quality: Garbage In, Garbage Out
What matters most for AIs is the data they're trained with.
If we train a model with only racist content, it will be a "racist AI", because it doesn't think and doesn't know what is wrong or right. It just learns patterns.
But, if we train a model with quality data, it can be really useful for complex tasks. Quality is way more important than quantity.
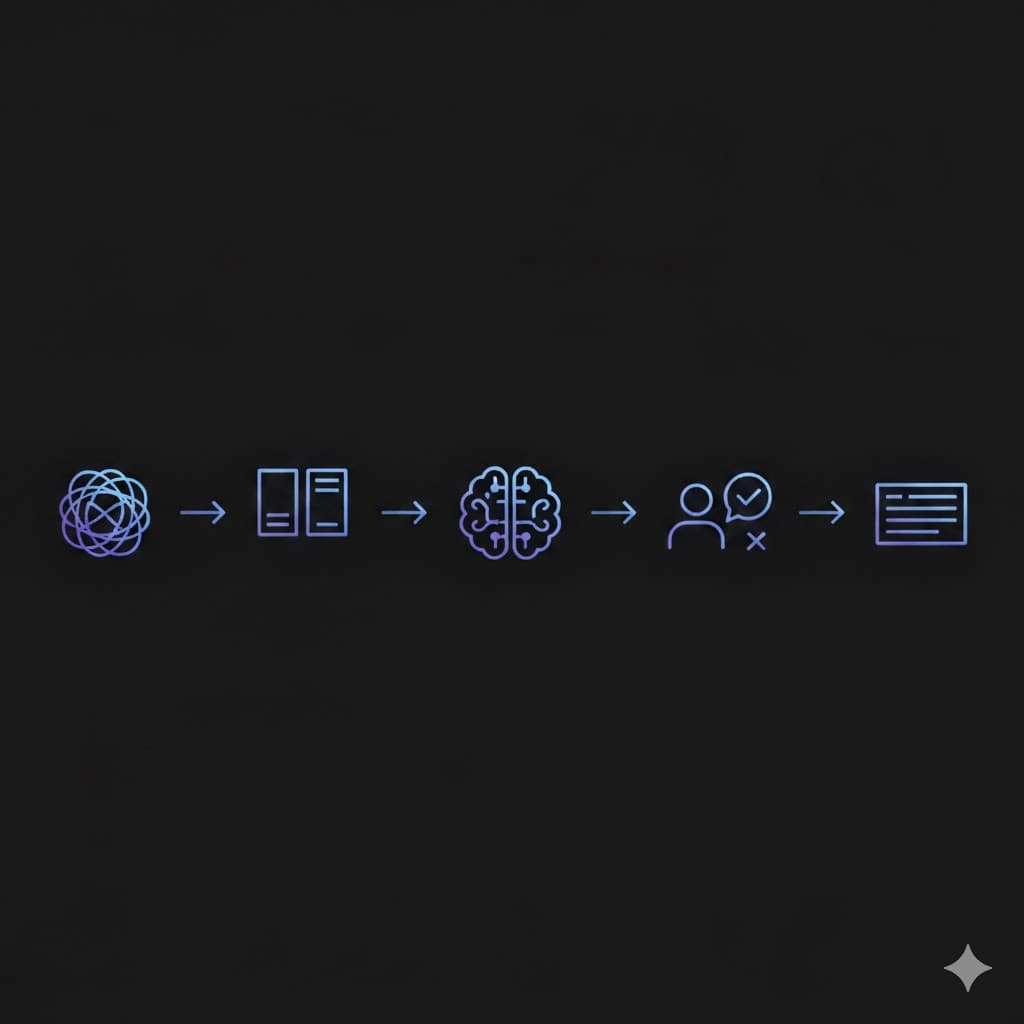
Putting It All Together
So, here's how everything connects: raw text gets broken into tokens, which the model processes through its parameters. During self-supervised learning, the model learns to predict the next token by reading massive amounts of data. Then RLHF refines its behavior to align with human preferences. Throughout this pipeline, data quality determines the ceiling of what the model can achieve.
Conclusion
Now that you have a better understanding of how AIs behave, I hope you stop thinking that AIs are thinking and being grateful when you say "thank you".
Understanding how AIs learn isn't just academic curiosity. It's practical knowledge that helps you work more effectively with these tools. When you know that a model learns through next-token prediction, you understand why prompting matters. When you understand RLHF, you see why models behave differently from their base versions, and why they look so polite.
This post is inspired by concepts from Chapter 2 of "AI Engineering" by Chip Huyen.
Of course, this is just a small overview. If you want to dive deeper, get the book and happy studying.
If this post helped you understand AIs better, leave a like and share it with someone who might find it useful.
Farewell.